**在C++中,内存分成5个区,但这五个区对于编译器的不同会有大致3中说法:**
##说法一:
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3、全局区(静态区)(static)— 全局变量和静态变量的存储是放在一块的。 - 程序结束后有系统释- 阅读剩余部分 -
#内置函数 (inline function)
**C和C++提升效率的方法: **C用宏定义,C++用内置函数。
**概念:**调用函数时需要一定的时间和空间的开销,内置函数在编译时将所调用函数的代码直接嵌入到主函数中,所以在程序执行的时候并不需要再调用函数。内置函数又称内联函数。
##内置函数定义格式:
**在声明函数和定义函数时在开头加上关键字"inline"。也可以只在其中一处声明"inline"。**
**实例:**
"的方式实现:
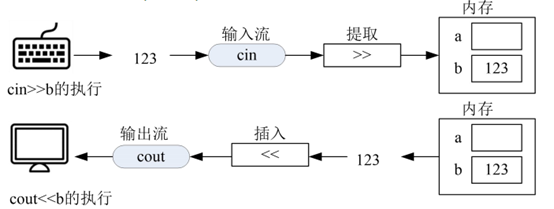
**注意:**流对象cin、cout和流运算符的定义存放在C++的输入输出流库iostream中;
cout、cin并不是C++本身提供的语句,运算符也不是C++本身提供的运算符
要在程序中使用cin、cout和流运算符,必须先: #include 。
#- 阅读剩余部分 -
#数据类型:
**基本类型的区别:**1.新增了布尔型(bool)/逻辑性。
**构造类型的区别:**1.在定义结构体类型变量时,其前的struct关键字可以被省略; 2.新增了类类型(class) 和 引用类型。
**其他区别:** 1.强制类型转换时数据类型外可不加括号。 2.新增动态内存分配的运算符 3.新增作用域运算符 4.变量的引用 5.新增了常变量
##布尔型数据及其运算:
**知识:**C和C++都用数值1代表"真",用0代表"假";特别是C- 阅读剩余部分 -
##包含头文件iostream
```cpp
#include //为了支持输入输出,需要在程序开始包含
```
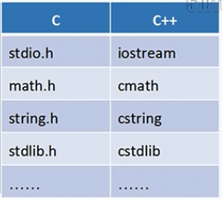
**C++的头文件:**
##使用命名空间std
```cpp
using namespace std; //定义命名空间std,下方的cout和endl就存在std内。
```
##创建主函数
```- 阅读剩余部分 -
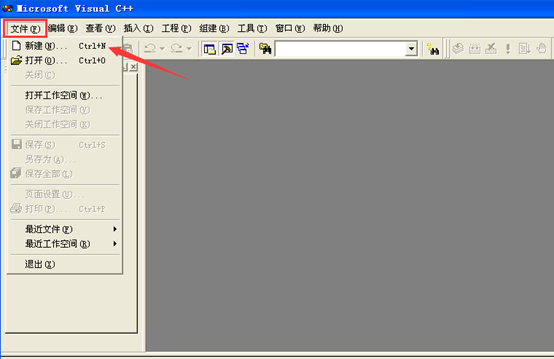
1、新建C程序文件,在新建面板中,选择“文件”选项卡,选择“C Source File”选项,同时输入该文件的名称,如下图所示。

1.函数体存储在代码区
2.局部变量存储在栈区
3.常量存储在常量区,赋值给变量的字面值都是常量
4.全局区存储着全局作用域的变量和所有静态变量,其中已初始化的变量占一块区域,未初始化的变量占另一块区域
5.使用malloc()进行动态分配的内存放在堆区
**例:**
```c
#include
i- 阅读剩余部分 -
#I.真随机数&伪随机数的基本定义
在这之前需要先明白一点:**随机数都是由随机数生成器(Random Number Generator)生成的**。
## 1.真随机数 TRUE Random Number
定义:真正的随机数是使用物理现象产生的:比如掷钱币、骰子、转轮、使用电子元件的噪音、核裂变等等,这样的随机数发生器叫做物理性随机数发生器,它们的缺点是技术要求比较高。
根据定义可以看到,真随机数是依赖于物理随机数生成器的。使用较多的就是电子元件中的噪音等较- 阅读剩余部分 -
#位运算符:
**概念:**位运算符用来对整型或字符型数据的二进制位(补码)进行操作。
##&按位与:
两个操作数中位都为1,结果才为1,否则结果为0。
```c
1&0=0,1&1=1,0&0=0
```
##|按位或:
两个位只要有一个为1,那么结果就是1,否则就为0。
```c
1|0=1,1|1=1,0|0=0
```
##^按位异或:
两个操作数的位中,相同则结果为0,不同则结果为1。
```c
1^1=0,1^0=1,0^- 阅读剩余部分 -
#字符处理函数

判断一个字符是否是字母中的一员: 如果是返回非0数字,如果不是返回0。
 
to- 阅读剩余部分 -
## 打开文件:
```c
FILE *文件指针 = fopen("文件目录","打开方式")
```
以只读方式打开1.txt
**文件打开类型:**

##文件指针位置:
**更改文件指针位置:**
```c- 阅读剩余部分 -


