##输出:
**System.out.print() ** //输出数据,不换行。
**System.out.println()** //数据数据,换行。
** :指所有东西的整合,当然也有的大型工程可以是由若干个小项目组合而成的。
**package (包)** : 用来识别项目中各个类之间的层次关系,每个项目可以有多个包。
**class(类文件)** : 每个包中有多个类文件,但是只有一个主文件,主文件用来调用其他类文件中的类。
总结:project采用package方式管理- 阅读剩余部分 -
1.左键双击对应需要断点的行的左侧,知道出现小圆点
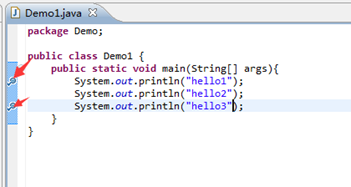
2.按下F11 进入调试界面:
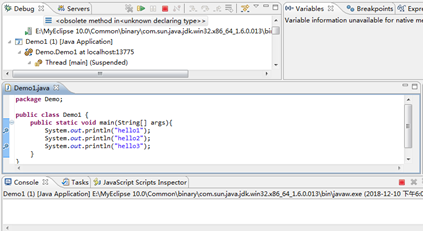
3.按下F8跳到下一个断点: 没有断点后停止脚本

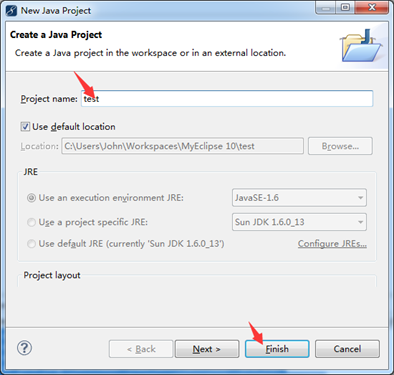
选择工程里的"src"->"New"->Package 创建Java包,包名不能以Java开头!

安装JAVA开发环境:JDK

##2.环境变量配置:
安装完成后,右击"我的电脑",点击"属性",选择"高级系统设置";

2\. 直接print出to_html()的内容可以发现将DataFrame转为了HTML中的格式
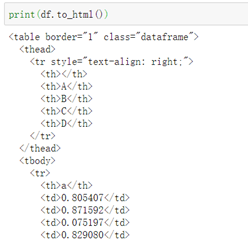
3\. 使用df.t- 阅读剩余部分 -
##读写CSV文件:
什么是CSV文件:以逗号分隔元素的文本文件。
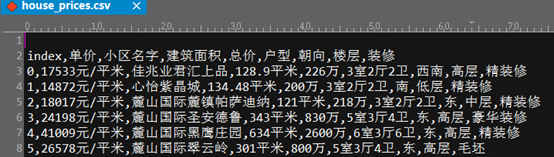
---
####读取CSV文件:
格式1:
```python
pd.read_csv('文件名')
```
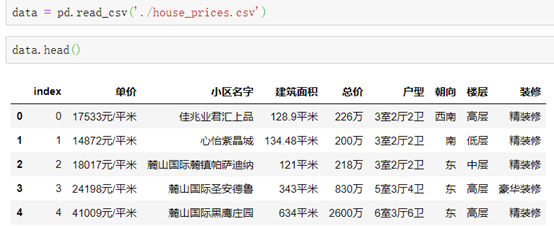
read_csv(- 阅读剩余部分 -
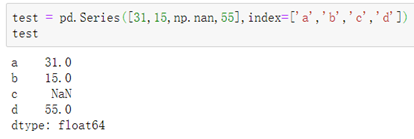
##NaN:
NaN数据即空数据,这种数据在数据处理中是非常常见的。
---
####一、初始化NaN数据:
使用numpy模块中的nan方法创建nan数据:
---
####二、赋值NaN数据:
直接赋值None即空数据:
, axis=1(默认为0,按index行;1按columns列)
##排序:
####按索引排序:
格式:
```python
pd.sort_index(ascending=True/False, axis=0/1)
```
Series的排序:

##作用于行列的函数:
```python
axis=0 表示求行元素; axis=1 表示求列元素。
```

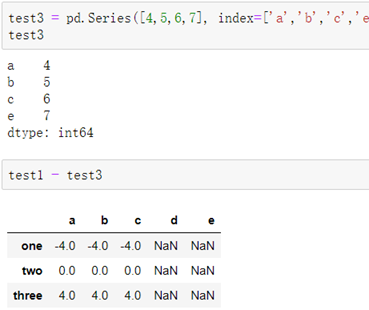
当DataFrame与Series之间的索引行标签不同时,所涉及的元素会以NaN空元素填充: