#数据结构-DataFrame
介绍:DataFrame数据结构和关系型表格类似,相当于将Series扩展到多维。由多列组成,各列数据类型可以不同。
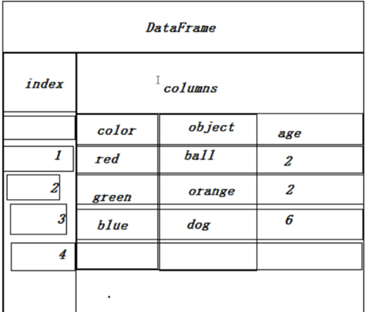
##一、 定义DataFrame:
统一格式:
```python
pd.DataFrame(矩阵,index=[行标签列表],columns=[列标签列表])
```
方式一- 阅读剩余部分 -
#数据结构-Series
介绍:Series结构的内部由两个相关联的数组组成,其中一个数组用来存放索引,另一个数组用来存放数据(numpy中的任意数据类型)。
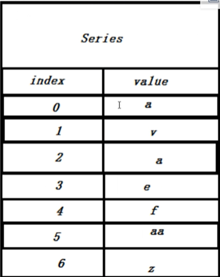
如图中两列左边一列作为存放索引的索引数组,右边一列作为存放数据的主索引。
1\. 导入模块:import pandas as pd
2\. 创建Series结构数据: - 阅读剩余部分 -
副本和视图:
1.在numpy中队数组做运算或操作时,返回的结果不是副本就是视图。
2.在numpy中所有的赋值运算不会为数组和数组中的任何元素创建副本。例如:创建一个数组a,将a赋值给b,修改a中的元素,结果b中的元素也会被修改。实际上a和b指向同一个地址空间。
3.数组切片操作返回的对象是原数组的视图。
4.要生成一个完整的副本,需要使用copy函数()。例:矩阵B = 矩阵A.copy()
5.向量化:向量化和广播这两个概念是Numpy内部实现- 阅读剩余部分 -
#数据文件的读写:
##内部数据读写:
方法一:二进制保存读取
```python
保存:np.save('文件名', 矩阵名)
读取:np.load('文件名')
```
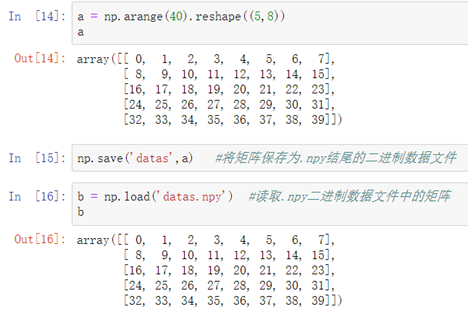
方法二:文本格式保存读取:
```python
保存:np.savetxt('文件名',矩阵)
读取:np.loadtxt('文件名')
```
- 阅读剩余部分 -
结构体中指定不同数据类型的符号: 其中数字1代表1字节即1*8=8位的数据类型。
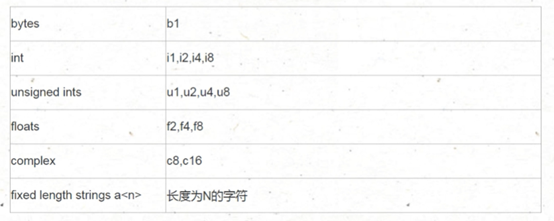
###定义结构体:
```python
np.array( [(元素1, 元素2...),], dtype=[('类型名1','数据类型1'), ('类型名2','数据类型2')......] )
```
)
水平拼接函数: np.vstack((矩阵A, 矩阵B, 矩阵C....))
```
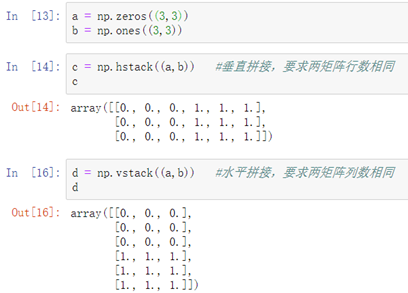
其他:
```python
向量垂直拼接成矩阵:np.column_stack((向量A, 向量B, 向量C...))
向量水- 阅读剩余部分 -
###自定义更改矩阵的形状:
```python
方式1-使用函数的方法: 矩阵.reshape((行, 列))
方法2-修改numpy属性: 矩阵.shape = (行, 列)
```
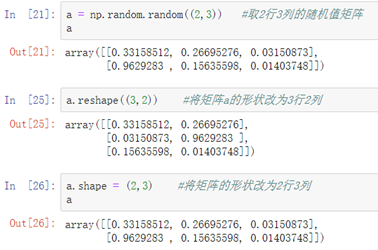
---
###将矩阵转为向量:
```python
方法1: 矩阵.ravel()
方法2: 矩阵.reshape(行*列) 或 - 阅读剩余部分 -
介绍:矩阵的条件判断是作用于每个元素的判断。
根据条件表达式返回布尔数组:
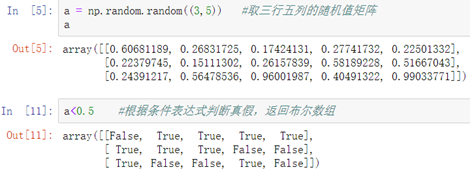
根据条件表达式得到符合条件元素的矩阵:

#索引:
##向量的索引:
向量的索引与普通列表的索引访问方式相同:

当一次需要获取多个索引的元素时需要使用 向量[[索引1, 索引2, 索引3....]] 的方式:

##矩阵的索引:
矩阵需要用双索引- 阅读剩余部分 -
##矩阵/向量的基本运算:
概念:某向量或矩阵与自然数加减乘除表示该向量或矩阵中的所有元素与该自然数加减乘除。
示例1:
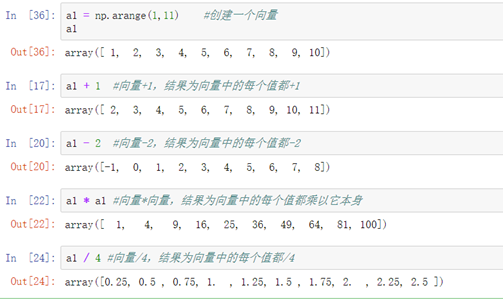
示例2:

##矩阵/向量的相互运算:
矩阵/向量的互相加减:
:
基础:一维数组=向量 二维数组=矩阵
定义:
>1. ndarray是整个numpy的基础,他是一个由同种元素类型的元素组成的多维数组。
2. 数组的维数和元素数量由型(shape)决定。如一个数组ListA的shape为(3,4),表示这是个3行4列的二维数组。
3. 数组的维统称为轴(axis),如x轴、y轴。轴的数量叫做秩(rank),如(x, y)的秩为2。
4. ndarray的特点是大小固定,即创建ndarray一旦指定- 阅读剩余部分 -


